

En un nuevo estudio, describen un modelo de código abierto para enseñarle, básicamente, básicamente cómo hacer un buen código de interfaz de usuario en el Swarai. Así es como lo hicieron.
En el papel UICoder: completa los grandes modelos de idioma para crear el código de interfaz de usuario mediante comentarios automáticosCuando mejoro los LLM en trabajos de escritura múltiple, incluida la escritura creativa y la codificación, los investigadores explican que todavía han considerado una buena idea ser considerada como un código confiable y diseñado. Tienen una buena idea:
Incluso en una datos serios con trabajos curiosos, los ejemplos del código de la interfaz de usuario son muy raros, y en algunos casos el código está por debajo de los ejemplos generales del código en los conjuntos de datos.
Para manejarlo, comenzaron un LLM de código abierto especialmente en codificación. Le dieron una lista de cuentas de IU, sugeridas para crear un gran conjunto de datos a partir de esas descripciones.
Desde entonces, corrieron a través de un compilador rápido, y en realidad está encendido, y luego se comparó un análisis de G0 -4V y un análisis en comparación con la interfaz concentrada con la descripción original.
Cualquier salida que no pudiera compilar y arrojar duplicado. Las salidas restantes formaron un conjunto de entrenamiento de alta calidad, que se utilizó para sintonizar el modelo.

Repitieron este proceso varias veces y cada repetición se creó un mejor código Swiftevi que antes. Eso, nutre un limpiador a DataSette.
Después de cinco rondas, los llaman un millón de programas Swift (996,000, precisos), llaman al UCoder más contacto con las indicaciones que el modelo inicial.

De hecho, dependiendo de sus pruebas, el modelo de almidón básico y las evaluaciones humanas en las dimensiones ututodificadas se han pospuesto sustancialmente.
El Sketcher volcó el GPT-4 en la calidad general.

Bad Kicker: el conjunto de datos real se evita por error el código Swift
Uno de los hechos más interesantes del estudio proviene de un pequeño tornillo. El modelo original de Starchat-Beta está entrenado principalmente en tres corporaciones:
- Tastes de colecciones de código con licencia compatible, un gran conjunto de datos (tokens 250b);
- Páginas web rastreadas;
- Openeracistint-Guanaco, un pequeño conjunto de datos de ajuste sugerido.
Problema debido a explicar a los investigadores de Apple:
Los datos de capacitación de Starchat-Beta no contienen ninguno de los datos que no son de atención. Al crear un conjunto de datos perfecto, el código Swift se vuelve a publicar accidentalmente, solo uno de los conjuntos de datos operandantes-guanaco se encuentra en las áreas de reacción (10,000 más). Cualquier ejemplos rápidos de Starchat-Beta durante la capacitación son de las páginas web de Craft, que es menor que el código de repositorio.
Esto significa que ya se envió a partir de los ejemplos que ya lo han visto de los ejemplos (no uno de sus datos de capacitación originales), pero la Apple ha sido construida por sus datacetas automáticas.
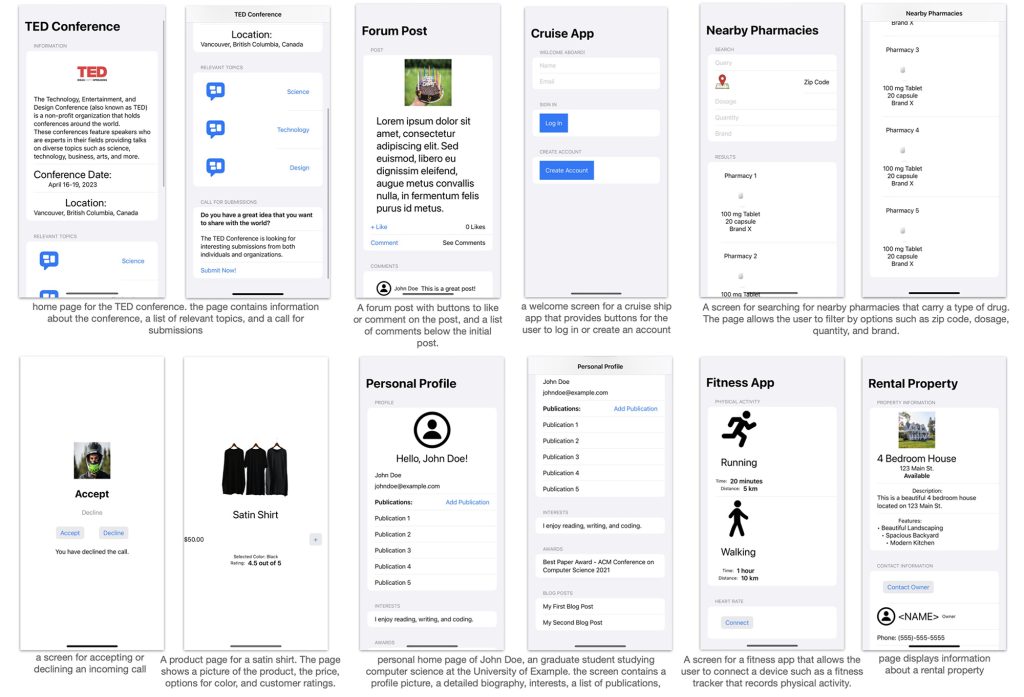
Fotos e íconos de archivo combinados. El código generado modelo no modificó ningún tipo que no sea actualizar la imagen
Nombres de activos. «
Esto en realidad puede poder generalizar que el UIIS es efectivo para implementar el uso de UII, en realidad puede generalizar a los investigadores a otros idiomas y kits de herramientas de interfaz de usuario «, es muy interesante.
Aprendizaje, YerCoder: modelos de idiomas grandes para crear código de interfaz de usuario a través de retroalimentación automática, Disponible en arxiv.
Ofertas en Amazon’s Amazon
FTC: Utilizamos los enlaces de afiliados automáticos de ingresos. Más.
















{kind=link}